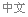|
|
The world's top Go player Lee Sedol (R) puts his first stone during the last match of the Google DeepMind Challenge Match against Google's artificial intelligence program AlphaGo in Seoul, South Korea, in this handout picture provided by Google and released by Yonhap on March 15, 2016.[Photo/Agencies] |
Google Deep Mind's AlphaGo artificial-intelligence program has beaten South Korean Go master Lee Sedol 4:1, sparking a debate world wide on whether AI could pose a threat to humankind.
The development of AI began decades ago. In 1997, Deep Blue developed by IBM defeated the world chess champion Garry Kasparov. In 2010, Apple added Siri (speech interpretation and recognition interface) to its iPhone, which understands the users' audio commands and replies accordingly-similar examples include Xiaobing of IBM and Jimi of jd.com.
But Siri, Xiaobing and Jimi can only deal with a limited number of questions, as they compare the user's command with those pre-installed in their "memories" and answer accordingly. The Deep Blue, on the other hand, relies heavily on fast computing; it decides its next move in a chess game mainly by evaluating the condition on the chessboard and comparing it with the manuals saved in its "memory". That's why it cannot win a Go game, which involves many more possibilities than chess.
AlphaGo, in this sense, is a big step forward because it uses multi-layered artificial neural network, or ANN, and reinforcement learning alGorithm, which can more exactly imitate the way a human brain thinks. AlphaGo repeatedly observes the Go board, analyzes it with its processor and makes the best choice. More importantly, it can store the decisions in its "memory" for future references. In other words, it can more efficiently "learn" and improve.
ANN has become a hot subject of research since the 1980s. It is already being used in many fields besides games. For example, the driverless car developed by Google "observes" the environment through sensors, using calculations to judge how things are moving, and chooses its route accordingly.
AlphaGo marks another step forward because the ANN it uses has more than 30 layers thanks to developers and faster computers. Each layer has multi-parameters that get adjusted each time it obtains information from the outside world, a process through which AlphaGo constantly optimizes its strategy. The more information it gets, the more exactly it can adjust the parameters to suit new situations.
Many people jocularly say AlphaGo is a hardworking student that "studies" hundreds of manuals every night. That may be a joke, but AlphaGo has learned a great deal about Go, or it couldn't have defeated Lee Se-dol. Let's hope its victory would make more people interested in AI research.
Yang Feng is an associate professor at the School of Automatics, Northwestern Polytechnical University.




I’ve lived in China for quite a considerable time including my graduate school years, travelled and worked in a few cities and still choose my destination taking into consideration the density of smog or PM2.5 particulate matter in the region.
Copyright 1995 - . All rights reserved. The content (including but not limited to text, photo, multimedia information, etc) published in this site belongs to China Daily Information Co (CDIC). Without written authorization from CDIC, such content shall not be republished or used in any form. Note: Browsers with 1024*768 or higher resolution are suggested for this site.
License for publishing multimedia online 0108263 Registration Number: 130349 ![]()